Your RAG System Is Not Confused. It Is Following Your Lead
You Tuned It Once. The Domain Changed a Hundred Times
Retrieval system behavior is determined long before anyone tunes a ranker or debates top-k. It is determined by the boundaries established at the start: segmentation rules, signal weights, and coverage assumptions. Those boundaries encode an internal model of the domain—its structure, its hierarchy, and its expected patterns of meaning.
When the domain evolves and the boundaries remain static, the system maintains fidelity to an obsolete structure. It is not instability. It is consistency applied to a world that has already shifted. Boundaries act as the system’s implicit worldview. When the worldview falls behind the domain, drift begins—not as an error, but as a steady misalignment between what the system preserves and what the domain now requires.
What Boundary Drift Actually Is
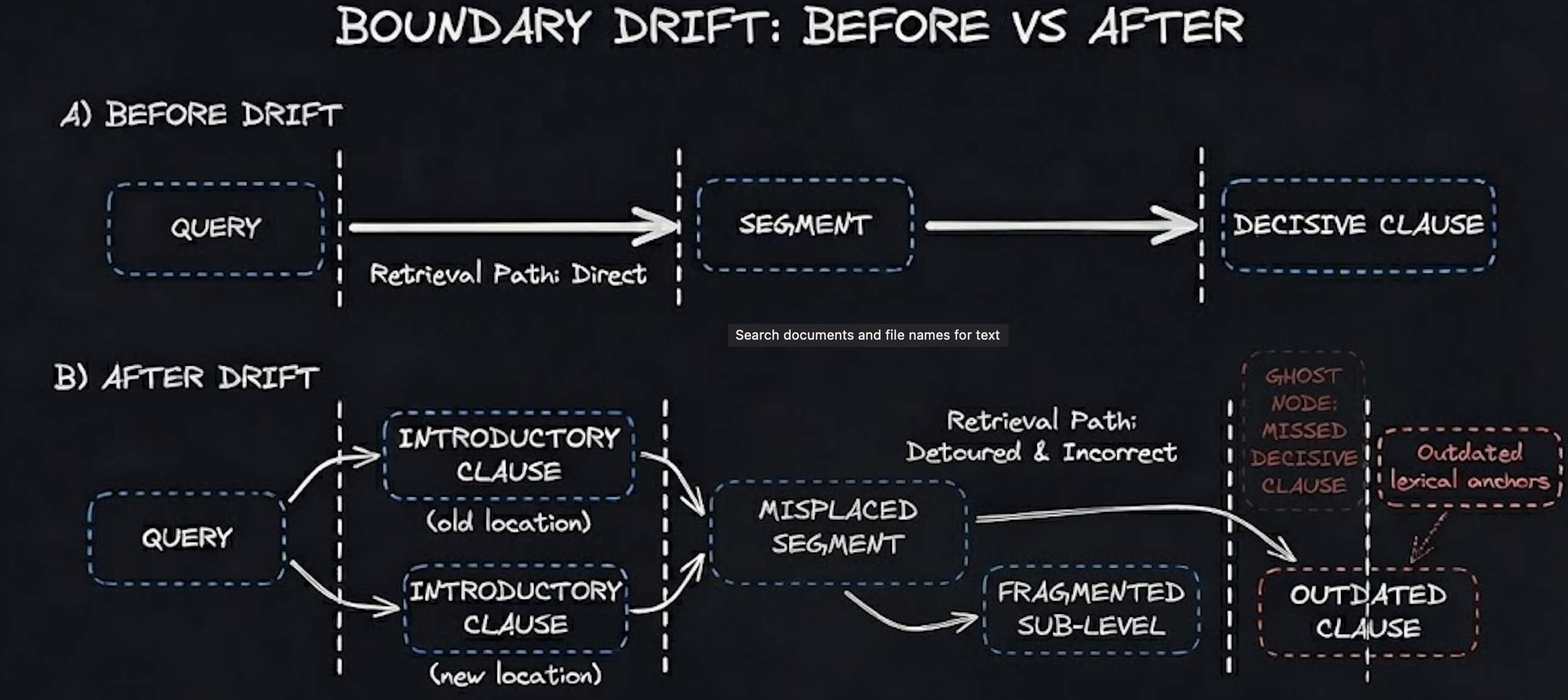
Boundary drift is the structural mismatch that forms when the domain’s hierarchy, phrasing patterns, or conceptual topology shifts and the retrieval layer continues executing its original assumptions. Chunking rules calibrated to a previous hierarchy begin segmenting through decisive clauses after heading depths change. Ranking logic tuned to older phrasing elevates passages that survive statistically but no longer represent governing meaning.
Externally, top-k results look plausible. Score distributions sit within normal variance. Coverage metrics appear unchanged. Internally, the segmentation and scoring regime is no longer aligned with the structure that actually governs meaning. What presents as relevance is often an artifact of an older structure encoded in the boundaries themselves.
To separate meaningful drift from normal variance, boundaries must be monitored numerically rather than intuitively. Corpus-level structural change beyond roughly five percent consistently predicts that segmentation no longer preserves decisive text. Anchor-query overlap shifts of thirty percent or more in top-5 results reliably correlate with downstream divergence in system outputs even when end-to-end accuracy appears stable.
Metrics for Unstructured and Semi-Structured Domains
Structured regulatory corpora expose drift cleanly because clause boundaries and hierarchies are explicit, but most domains are messier. Product documentation, help centers, research repositories, and support transcripts mix narrative text, tables, screenshots, and ad-hoc headings; drift appears first in how concepts co-locate rather than in whether a specific clause moved one section deeper.
One class of metrics is continuity-based. Query–map continuity measures how stable the path of a query through the corpus remains over time. A continuity score dropping from 0.9 to 0.7, or a median decisive-span rank moving from 3 to 11, is evidence that boundaries are no longer aligned even if precision@k has not yet fallen.
How Drift Shows Up Before You Can Measure It
Domain experts perceive drift before telemetry does. Reports that answers feel outdated, overly cautious, or generic are early indicators that retrieval is anchored to a superseded conceptual structure. These are not qualitative complaints; they are observations of structural misalignment.
Engineering responses often target the symptom rather than the cause. Teams tighten prompts, add filters, or constrain sampling parameters. These interventions suppress downstream noise while leaving upstream misalignment intact. Drift accumulates because the system continues honoring the boundaries it was given. Obedience becomes the failure mode.
The Project That Made Drift Impossible to Ignore
A compliance engine operating on roughly 28,000 documents made the pattern explicit. At launch, a suite of 312 anchor queries achieved top-3 clause alignment near 0.92. Three months later, analysts described the responses as heavier and more cautious. No telemetry supported the claim. The fracture lived in the structure. Seventeen percent of the corpus adopted new heading depths. Chunking rules tuned to the earlier hierarchy bisected clauses carrying regulatory force. The system had not degraded. It was faithfully modeling a regulatory world the domain had already left behind.

The System Built to Stay Aligned
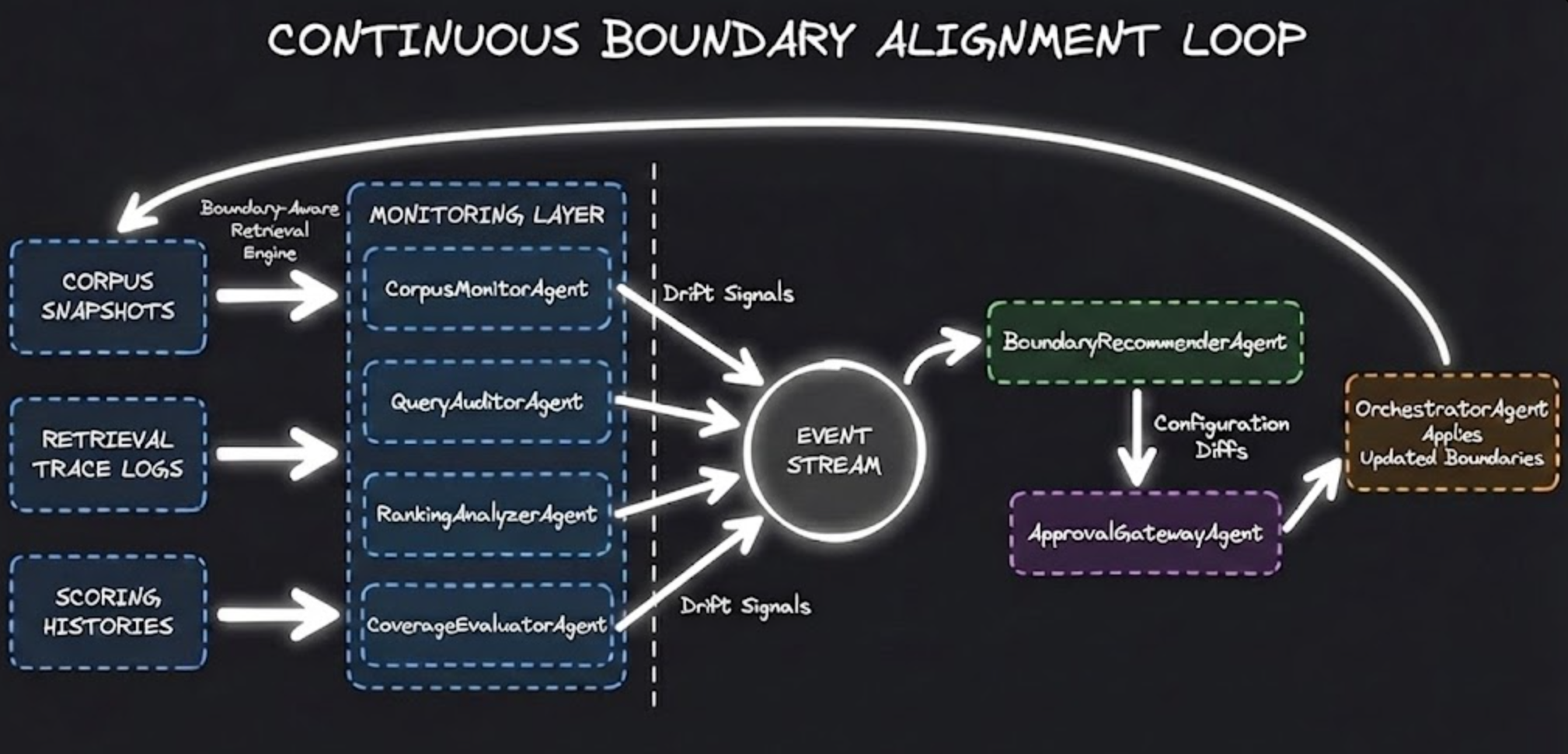
The solution was to build an architecture that treats drift as a primary signal rather than an afterthought. Each component behaves as an observer responsible for detecting how the domain is changing and ensuring boundaries update before misalignment becomes visible.
CorpusMonitorAgent
Fingerprinted documents using MinHash and SimHash, tracking heading depth, clause sequencing, and template shifts. When more than five percent of documents adopted new patterns, it signaled that segmentation and indexing assumptions likely no longer preserved decisive text. Structural drift always precedes semantic drift.
QueryAuditorAgent
Maintained historical retrieval maps for anchor queries. It replayed these queries on a fixed cadence and measured top-k overlap against baseline paths. A thirty-percent shift in top-5 results reliably indicated that the domain had moved beneath the system.
RankingAnalyzerAgent
Monitored score distributions across lexical and dense similarity channels. Rising boilerplate frequency, reappearance of deprecated phrasing, or compression of score variance signaled that the ranking logic still reflected an older linguistic regime.
BoundaryRecommenderAgent
Transformed drift signals into auditable proposals — updated chunking heuristics, recalibrated ranking weights, scheduled embedding refresh cycles. Each proposal included projected precision, coverage, and cost impacts. Drift becomes actionable only when represented as concrete boundary updates.
ApprovalGatewayAgent
Enforced structured oversight. It routed proposals for review, recorded rationales, and maintained a ledger of accepted and rejected adjustments. Silent automation is not alignment.
Why This Level of Automation Matters
Retrieval systems rarely fail abruptly. They fail by continuing to operate correctly against an obsolete structure. Automation does not replace judgment. It preserves it. It converts structural change into telemetry, domain movement into explicit signals, and early discomfort into actionable alignment decisions. In a moving domain, the responsibility is not to tune a system once, but to keep its boundaries aligned as the world continues to shift.